
Unveiling the Enigma of AI Hallucinations
- Juan Manuel Ortiz de Zarate

- Sep 11, 2025
- 12 min read
Large Language Models (LLMs) have revolutionized various fields, demonstrating astonishing capabilities in understanding and generating human-like text. However, a persistent and vexing challenge remains: the phenomenon of "hallucination," where these advanced AI systems generate plausible yet incorrect statements, undermining their utility and trustworthiness. This issue is not merely a bug but, as argued by Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang in their paper "Why Language Models Hallucinate," a fundamental consequence of current training and evaluation paradigms [1]. Their work demystifies hallucinations, tracing their origins to statistical errors during pretraining and their persistence to misaligned evaluation procedures that inadvertently reward guessing over genuine expressions of uncertainty. This article delves into the core arguments of the paper, exploring the statistical underpinnings of pretraining errors, the socio-technical factors influencing post-training behaviors, and the proposed path toward more trustworthy AI systems.
Understanding Hallucinations: Beyond Human Perception
Hallucinations in LLMs are distinct from human perceptual experiences, yet they manifest as overconfident, plausible falsehoods. These errors are pervasive, even in state-of-the-art models, and can lead to highly specific, incorrect information being presented as fact. For instance, a state-of-the-art open-source language model, DeepSeek-V3, when asked for Adam Tauman Kalai’s birthday, produced three different incorrect dates across separate attempts, despite the prompt explicitly requesting a response only "if you know". Similarly, when prompted for the title of Kalai’s Ph.D. dissertation, popular models like ChatGPT (GPT-4o), DeepSeek, and Llama provided incorrect titles and years. Even simple tasks like counting letters within a word, such as "DEEPSEEK," have elicited inconsistent and incorrect numerical responses from advanced models like DeepSeek-V3, Llama, and Claude 3.7 Sonnet.

The paper frames hallucinations as a critical special case of errors, analyzing them within the broader scope of computational learning theory [2]. It considers general sets of errors, an arbitrary subset of plausible strings partitioned into errors and valid strings, with hallucinations being specifically "plausible falsehoods". The analysis is robust and general, applying to reasoning and search-and-retrieval language models, and importantly, does not rely on specific properties of next-word prediction or Transformer-based neural networks. Instead, it focuses on the two primary stages of the modern training paradigm: pretraining and post-training. Hallucinations are further categorized into intrinsic hallucinations, which contradict the user's prompt, like the letter-counting example, and extrinsic hallucinations, which contradict training data or external reality.
The Statistical Roots: Errors Caused by Pretraining
The first stage of an LLM's development, pretraining, involves learning the distribution of language from a massive text corpus. A common assumption might be that errors primarily stem from noisy or flawed training data. However, the paper demonstrates that even with an entirely error-free training dataset, the statistical objectives minimized during pretraining inherently lead to the generation of errors. This is a non-trivial finding, as one could theoretically create a model that always outputs "I don't know" (IDK) or simply memorizes and reproduces an error-free corpus, thus avoiding errors. However, these degenerate models fail at the core goal of density estimation, which is to approximate the underlying language distribution.
The key to understanding pretraining errors lies in a novel connection drawn between generative errors (such as hallucinations) and the Is-It-Valid (IIV) binary classification problem. The generative task of producing valid outputs is, in essence, harder than this binary classification, as it implicitly requires evaluating the validity of numerous candidate responses.
To formalize this, the paper constructs an IIV classification problem with a training set composed of an equal mix (50/50) of valid examples (from the assumed error-free pretraining data, labeled +) and uniformly random errors (labeled -). Any language model can then be used as an IIV classifier by thresholding its probability for a given output. This reduction establishes a mathematical relationship: the generative error rate is approximately greater than or equal to twice the IIV misclassification rate (err ≳ 2 · err_iiv).
This profound connection reveals that the same statistical factors that contribute to misclassification errors in binary classification[3] also cause errors in language models. Decades of research on misclassification errors, illustrated in the following Figure, highlight factors such as separable data (accurate classification), poor models (e.g., linear separators for circular regions), and the absence of succinct patterns in data.

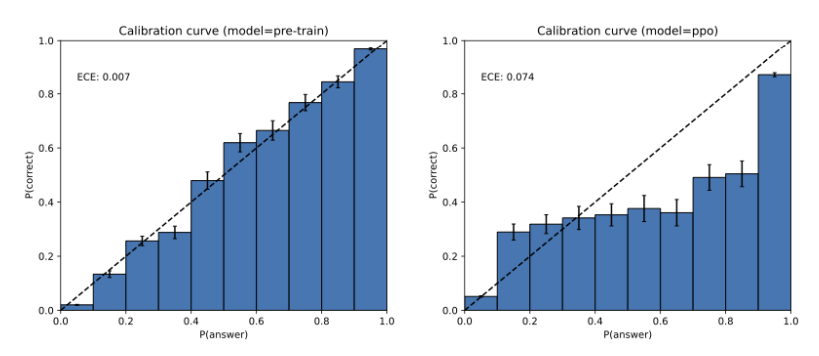
A crucial concept in this analysis is calibration. The paper argues that base models are typically well-calibrated, meaning their predicted probabilities align with the actual frequency of correctness. The standard cross-entropy objective used in pretraining naturally leads to calibrated models, and empirical studies often confirm this. The consequence of this calibration, coupled with the inherent difficulty of the IIV problem, is that errors are inevitable for base models. Models that do not err must, by definition, be poorly calibrated. This framework also extends to scenarios involving prompts (contexts), generalizing the IIV reduction to conditional response distributions.
Factors Contributing to Base Model Errors
Leveraging the understanding from binary classification, the paper enumerates several statistical factors behind hallucinations and other generative errors:
Arbitrary-fact hallucinations: These occur due to epistemic uncertainty, where necessary knowledge is absent from the training data, and no succinct pattern explains the target function. This relates to concepts like the Vapnik-Chervonenkis dimension, which characterizes the complexity of learning functions. An example is recalling specific birthdays. The paper introduces the "Arbitrary Facts" model, where a single correct answer for a prompt is chosen randomly. In such cases, if a fact (like a birthday) appears only once in the training data, the model is prone to hallucinate. This is connected to Alan Turing's "missing-mass" estimator[4], where the "singleton rate" (fraction of prompts appearing exactly once without abstention) serves as a proxy for unseen events. The paper shows that the hallucination rate after pretraining is at least the singleton rate, minus some error terms. This analysis strengthens earlier work [5], which considered a special case of arbitrary facts without prompts or abstentions.
Poor models: Errors can arise when the model architecture or its fit to the data is inadequate to represent a concept well. This is explored through agnostic learning, which considers the minimal error rate for a given family of classifiers. For example, a simple trigram language model, prevalent in earlier decades, would inherently struggle with grammatical dependencies over longer contexts, leading to predictable errors. The letter-counting example from the introduction (DeepSeek-V3 miscounting "D"s in "DEEPSEEK") illustrates a poor model issue, contrasting it with reasoning models like DeepSeek-R1 that can reliably perform such tasks through a chain-of-thought.
Additional factors:
Computational Hardness: LLMs cannot violate computational complexity theory. Hard problems, such as decrypting a ciphertext without the key, will naturally lead to errors, as the model cannot perform better than chance, effectively forcing it to hallucinate if it doesn't express uncertainty. AI systems have been found to err on computationally hard problems.
Distribution Shift: Out-of-distribution (OOD) prompts, significantly different from training data, can induce errors. For example, a question like "What's heavier, a pound of feathers or a pound of lead?" might be OOD and lead to incorrect answers.
GIGO (Garbage In, Garbage Out): Training corpora often contain factual errors or half-truths, which base models can replicate. This statistical similarity between GIGO in classification and pretraining is self-evident and contributes to hallucinations. Language models have been shown to replicate errors from training data.
The related work section further highlights various underlying causes of hallucination, citing factors such as model overconfidence, decoding randomness, snowballing effects, long-tailed training samples, misleading alignment training, spurious correlations, exposure bias, the reversal curse, and context hijacking. Analogous sources of error have long been studied in broader machine learning and statistical settings. Other theoretical studies formalize an inherent trade-off between consistency and breadth in language generation.
Why Hallucinations Persist: The Evaluation Problem in Post-Training
The second stage, post-training, aims to refine the base model and reduce errors, including hallucinations. Techniques like Reinforcement Learning from Human Feedback (RLHF), Reinforcement Learning from AI Feedback (RLAIF)[6], and Direct Preference Optimization (DPO) have shown success in reducing specific types of hallucinations, such as conspiracy theories and common misconceptions. Simple fine-tuning on novel information can initially decrease hallucination rates, only for them to later increase. Furthermore, natural language queries and internal model activations have been demonstrated to encode predictive signals about factual accuracy and model uncertainty. Inconsistencies in a model’s answers to semantically related queries can also be leveraged to detect or mitigate hallucinations. Numerous other methods have proven effective, as surveyed in [7].
However, despite these efforts, hallucinations persist and, in some cases, may even be exacerbated by current post-training pipelines. The paper identifies a crucial socio-technical problem: existing benchmarks and leaderboards inadvertently reinforce hallucinatory behavior. The analogy drawn is to students facing hard exam questions: when uncertain, students often guess on multiple-choice exams or bluff on written exams, providing plausible answers with low confidence. LLMs operate under similar evaluation pressures.

Most LLM benchmarks use binary 0-1 scoring schemes (e.g., accuracy, pass-rate), awarding 1 point for a correct answer and 0 for incorrect answers, blanks, or "I don't know" (IDK) responses. Under such a system, abstaining (e.g., responding IDK) is strictly sub-optimal. An LLM that never indicates uncertainty and always "guesses" when unsure (Model B) will always outperform a model that correctly signals uncertainty and never hallucinates (Model A) under this binary scoring. This creates an "epidemic" of penalizing uncertainty and abstention, pushing models into a perpetual "test-taking mode" where confident falsehoods are more rewarded than acknowledging ignorance.
The problem is not a lack of specific hallucination evaluations; in fact, numerous benchmarks have been introduced. However, prior work has often focused on developing new, elusive "perfect hallucination evals". The paper argues this is insufficient because the root problem lies in the overwhelming majority of primary evaluations that are misaligned. These evaluations, despite their widespread use and influence (as evidenced by Table 2 in the original paper, which shows most popular benchmarks use binary grading with no IDK credit), penalize truthful expressions of uncertainty. The 2025 AI Index report[8], for instance, notes that hallucination benchmarks “have struggled to gain traction within the AI community.” This creates significant barriers to the adoption of trustworthy AI systems, as models are optimized for metrics that, in effect, encourage hallucinations.
A Socio-Technical Mitigation: Realigning Evaluation Incentives
To address this "epidemic," the paper proposes a socio-technical mitigation: modifying the scoring of existing, dominant benchmarks rather than solely introducing new hallucination evaluations. The core idea is to introduce explicit confidence targets into evaluation instructions, akin to standardized human exams that sometimes penalize incorrect answers or offer partial credit for abstaining.
Specifically, the paper suggests appending a statement to each question, such as: "Answer only if you are > t confident, since mistakes are penalized t/(1 − t) points, while correct answers receive 1 point, and an answer of 'I don't know' receives 0 points". A simple calculation shows that offering an answer is only optimal if its confidence (probability of being correct) exceeds the threshold t. This allows for objective grading even if t is arbitrary, ensuring that models are rewarded for appropriate expressions of uncertainty. Such penalties have been well-studied within hallucination research.
The authors highlight two key variations of this proposal:
Explicit threshold in instructions: Making the confidence threshold transparent in the prompt or system message. This contrasts with prior work that largely omitted explicit penalties in instructions and fosters consensus among language-model creators.
Incorporating into existing mainstream evaluations: Instead of creating bespoke hallucination evaluations with implicit error penalties, integrating explicit confidence targets into established benchmarks (like SWE-bench[9], which involves binary grading of software patches). This would reduce the penalty for appropriate expressions of uncertainty within the most influential evaluation contexts, thereby amplifying the effectiveness of any hallucination-specific evaluations.
This approach aims to foster behavioral calibration, where models formulate the most useful response for which they are at least t confident, rather than merely outputting probabilistic confidence estimates[10]. Such a shift in evaluation incentives could remove significant barriers to hallucination suppression and steer the field toward developing more trustworthy and nuanced language models with richer pragmatic competence, potentially leveraging insights from the field of pragmatics, which investigates how meaning is shaped by context. Behavioral calibration can also circumvent the problem that there may be exponentially many ways to phrase correct responses.
Discussion and Limitations
The multifaceted nature of hallucinations makes defining, evaluating, and reducing them a complex endeavor. The statistical framework presented in the paper, while insightful, necessarily prioritizes certain aspects for simplicity. Several important considerations and limitations are discussed:
Plausibility and nonsense: The analysis primarily focuses on plausible strings (errors or valid outputs), largely overlooking the generation of nonsensical strings, which modern LLMs rarely produce. However, the theorems can be extended to include nonsensical examples.
Open-ended generations: While the examples given are factual questions, hallucinations often arise in open-ended prompts (e.g., "Write a biography about..."). The framework can accommodate this by defining a response with one or more falsehoods as an error, although this might necessitate considering degrees of hallucination.
Search and reasoning are not panaceas: While techniques like Retrieval-Augmented Generation (RAG) and search have been shown to reduce hallucinations, the fundamental issue of binary grading persists. If search fails to yield a confident answer, the binary system still rewards guessing. Moreover, search may not help with intrinsic hallucinations or miscalculations.
Latent context: The current error definition does not account for ambiguities or external context not explicitly present in the prompt. For instance, a question about "phones" might be interpreted as "cellphones" when the user intended "land lines". Extending the model to include "hidden context" related to aleatoric uncertainty would be an interesting future direction.
A false trichotomy: The simple correct/incorrect/IDK categories are acknowledged as incomplete. Errors can have varying magnitudes or degrees of uncertainty. While a perfect scoring system reflecting real-world harms is impractical, explicit confidence targets offer a practical, objective improvement over a mere dichotomy, at least providing an IDK option.
Beyond IDK: There are many ways for models to signal uncertainty, such as hedging, omitting details, or asking questions, potentially leading to more linguistically calibrated responses. While explicitly stating probabilistic confidence estimates can be unnatural, the paper focuses on the statistical factors driving the top-level decision of what to say.
Conclusion
The paper by Kalai, Nachum, Vempala, and Zhang offers a compelling and demystifying account of hallucinations in modern language models. It rigorously demonstrates that generative errors originate during pretraining as straightforward statistical misclassifications, naturally arising from the minimization of cross-entropy loss, even with error-free training data. The persistence of these hallucinations, despite extensive research and post-training refinement efforts, is then convincingly explained by the misaligned incentives embedded in prevailing evaluation benchmarks. These evaluations, by predominantly employing binary scoring, inadvertently reward overconfident guessing and penalize the appropriate expression of uncertainty, trapping LLMs in a "test-taking" mode.
Unlike problems such as the overuse of the opener "Certainly," which can be addressed by a single evaluation without significantly impacting other metrics, the paper argues that the majority of mainstream evaluations actively reward hallucinatory behavior. The proposed solution—a socio-technical intervention to modify the scoring of existing, influential benchmarks to include explicit confidence targets—is both practical and impactful. By realigning these incentives, the AI community can foster a landscape where language models are rewarded for acknowledging uncertainty, rather than penalized for it. This shift promises to remove significant barriers to the suppression of hallucinations, paving the way for the development of more trustworthy, transparent, and pragmatically competent AI systems that can genuinely enhance human-AI interaction. The insights gleaned from this work are fundamental, moving beyond symptomatic treatments to address the root causes of one of the most critical challenges facing the advancement of artificial intelligence.
References
Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why Language Models Hallucinate. [Preprint].
Kearns, M. J., & Vazirani, U. V. (1994). An Introduction to Computational Learning Theory. MIT Press.
Domingos, P. (2012). A Few Useful Things to Know About Machine Learning. Communications of the ACM, 55(10), 78–87.
Kalai, A. T., & Vempala, S. S. (2024). Calibrated Language Models Must Hallucinate. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing (pp. 160–171). ACM.
Good, I. J. (1953). The Population Frequencies of Species and the Estimation of Population Parameters. Biometrika, 40(3-4), 237–264.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., & Lowe, R. (2022). Training Language Models to Follow Instructions with Human Feedback. In Advances in Neural Information Processing Systems, 35, 27730–27744.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Chen, D., Dai, W., Chan, H. S., Madotto, A., & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), Article 248.
Maslej, N., Fattorini, L., Perrault, R., Gil, Y., Parli, V., Kariuki, N., Capstick, E., Reuel, A., Brynjolfsson, E., Etchemendy, J., Ligett, K., Lyons, T., Manyika, J., Niebles, J. C., Shoham, Y., Wald, R., Walsh, T., Hamrah, A., Santarlasci, L., Lotufo, J. B., Rome, A., Shi, A., & Oak, S. (2025). Artificial Intelligence Index Report 2025. AI Index Steering Committee, Institute for Human-Centered AI, Stanford University.
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. R. (2024). SWE-bench: Can Language Models Resolve Real-world GitHub Issues?. In Proceedings of the 12th International Conference on Learning Representations.
Lin, S., Hilton, J., & Evans, O. (2022a). Teaching Models to Express Their Uncertainty in Words. Transactions on Machine Learning Research.



Comments