
The Lightning Mind
- Juan Manuel Ortiz de Zarate

- Oct 22, 2025
- 9 min read
As large language models (LLMs) grow, they develop the memory of titans and the appetite of supercomputers. The longer the “context”, the amount of text a model can attend to at once, the heavier the computational bill. Reading a 100-page novel in a single glance requires the model to process billions of relationships between words. Every token, or word fragment, interacts with every other, creating a mathematical jungle that scales quadratically with length.
DeepSeek-V3.2-Exp [1] enters this jungle with a machete called DeepSeek Sparse Attention (DSA). Instead of trying to read every leaf, it learns which trees matter. It is a new way for neural networks to decide which bits of past information deserve attention, and which can safely fade into the background.

From Dense Thinking to Selective Focus
Traditional transformers use dense attention: every token in a sequence compares itself with all others. That’s computationally beautiful but wasteful. Imagine trying to recall a specific memory by replaying your entire life, efficient it is not. Sparse attention, by contrast, asks: Which parts of the past are actually relevant to this thought?
The DSA mechanism answers this question through two key inventions: a lightning indexer and a fine-grained token selector.
The lightning indexer is a quick, low-precision module (implemented efficiently in FP8 format) that assigns a score between a “query” token and its predecessors. Think of it as a radar that scans previous words and decides which ones are most likely to matter. The top-scoring tokens, the “top-k”, are then chosen for detailed attention.
Once those tokens are picked, the main model applies full attention only to that reduced set. The rest are ignored, drastically cutting the computational load. The process is like an editor who skims hundreds of pages and highlights only the relevant paragraphs before a deep review.
Plugging Sparse Attention into an Existing Brain
DeepSeek-V3.2-Exp wasn’t built from scratch. It extends DeepSeek-V3.1-Terminus, a long-context model that could already handle 128,000 tokens, roughly a 300-page book, at once. The researchers wanted to make it faster without damaging its intelligence.
To achieve this, they kept most of the original architecture but replaced the traditional dense attention layer with the new DSA mechanism. Crucially, they instantiated DSA under something called MLA (Multi-Latent Attention) [2], an earlier DeepSeek innovation that shares “key-value” information efficiently across different attention heads [6]. Inside MLA, the DSA operates in multi-query mode (MQA) [5], meaning all the model’s “heads” (mini-brains looking at different aspects of language) share the same memory entries. This not only saves computation but also mirrors how human focus works: we use the same memory to reason about different aspects of a problem.

The Two-Stage Training Dance
Training a sparse model is tricky. It’s like teaching someone to speed-read before they know what’s important. The DeepSeek team used a two-stage process to ease the transition from dense to sparse thinking.
1. Dense Warm-Up:
First, the model keeps its full attention active while the new lightning indexer learns to mimic it. The indexer watches how dense attention distributes its focus across tokens and tries to replicate that pattern. This alignment is trained with a loss function based on Kullback–Leibler divergence [4], which measures how far two probability distributions are from each other. Essentially, the indexer learns to guess which words dense attention would care about.
2. Sparse Training:
Once the indexer is competent, the model switches to sparse mode, using only the top-k tokens per query. Now, all parameters are trained together so that the network adapts to this new, leaner attention style. The researchers trained it for billions of tokens, selecting 2048 relevant tokens per query. That’s still a lot, but far less than the full 128,000 possibilities.
During this phase, they carefully separated the optimization of the indexer and the main model. The indexer learned from its own loss, while the rest of the model learned from standard language modeling. This separation prevents the indexer’s learning noise from confusing the main model.
Post-Training: Giving the Model Personality
After the main training, DeepSeek-V3.2-Exp underwent post-training to refine its reasoning, problem-solving, and alignment with human preferences. The process resembles a finishing school for AIs.
The team used a specialist distillation step: they trained smaller, domain-focused models on tasks like mathematics, competitive programming, logical reasoning, coding, and search. These “specialists” then generated data for the main model, teaching it nuanced reasoning styles in each area.
Next came reinforcement learning (RL), a stage where the model learns by trial and reward. DeepSeek employed Group Relative Policy Optimization (GRPO)[7], a variant of policy optimization tailored for large models. Instead of training on multiple RL stages (which can make models forget earlier skills), they merged reasoning, agentic, and alignment objectives into one unified stage. This balanced approach helped the model stay versatile, good at reasoning, coding, and chatting, without suffering the infamous “catastrophic forgetting” problem.
What Did It Learn?
Benchmarks [3] tell part of the story. The researchers compared DeepSeek-V3.2-Exp with its predecessor on a range of tests: general reasoning (MMLU-Pro), question answering (GPQA), math (AIME and HMMT), programming (LiveCodeBench and Codeforces), and agentic tasks like autonomous browsing and software verification.
The results? Almost identical performance, despite the new model using sparse attention. In some areas, like code generation and math reasoning, the differences were statistically negligible. In long-context reasoning, its primary goal, DeepSeek-V3.2-Exp was significantly faster and cheaper.
One caveat: it generated fewer “reasoning tokens” during chain-of-thought tasks, slightly lowering its scores on ultra-complex benchmarks like Humanity’s Last Exam. But when researchers adjusted for token length, the gap vanished. In practice, this means the model reached conclusions more concisely, not less intelligently.

Measuring Speed: From O(L²) to O(Lk)
Here lies the heart of the breakthrough. Traditional attention mechanisms scale with the square of the context length, O(L²), because every token compares with every other. DSA reduces this to O(Lk), where k is the number of selected tokens, usually much smaller than L.
Although the lightning indexer technically still computes pairwise scores, it’s lightweight and operates in reduced precision, making the cost negligible. When tested on NVIDIA H800 GPUs (each rented at roughly $2/hour), the model achieved a significant end-to-end cost reduction, especially during long-context inference. Prefilling (the initial stage where the model reads input) and decoding (when it generates text) both became cheaper.
A graph from the paper shows the cost per million tokens dropping dramatically as sequence length increases. Where dense attention costs ballooned beyond $2 per million tokens at 128K length, DSA cut it by more than half. In economic terms, it’s the difference between flying private and taking a high-speed train: same destination, smaller carbon footprint.
Stability Under Reinforcement Learning
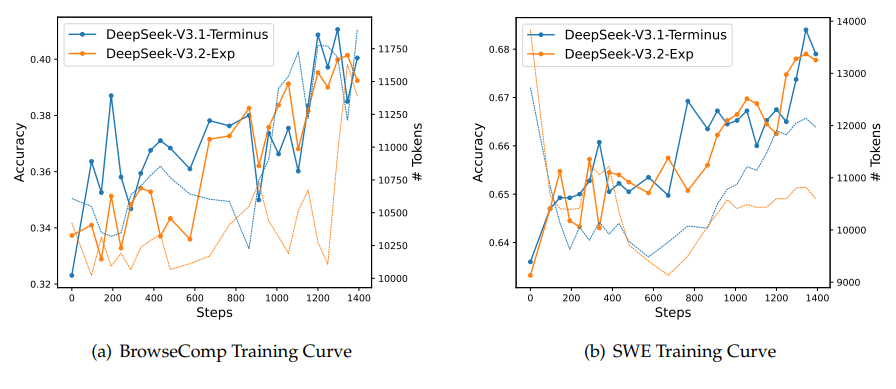
Efficiency is meaningless if the model becomes unstable during training. Sparse attention mechanisms often struggle with convergence; they can oscillate or diverge because information pathways change dynamically. The DeepSeek team plotted reinforcement learning curves for reasoning and code-agent tasks and found parallel stability between V3.1-Terminus and V3.2-Exp.
The accuracy on tasks like BrowseComp and SWE Verified increased steadily, and the output token lengths remained consistent, showing that the model’s internal representation stayed balanced. This stability is a quiet triumph: it suggests sparse attention can be trained reliably at scale, not just simulated in research prototypes.
Why Sparse Attention Matters Beyond Speed
Sparse attention isn’t just an engineering trick; it’s a conceptual step toward more cognitive AI. Dense attention mimics brute-force memory, looking everywhere, always. Sparse attention introduces selectivity, which is a hallmark of intelligence. Humans constantly filter sensory data, focusing on what matters. A machine that can learn to “forget” strategically is edging closer to human-like efficiency.
In neuroscience, this parallels sparse coding, the brain’s tendency to represent information using a small number of active neurons. The cortex doesn’t store every pixel of a visual scene; it encodes edges, movement, and salient patterns. Similarly, DSA learns to represent long sequences by focusing on the linguistically or semantically crucial fragments.
The Bigger Picture: The Long-Context Arms Race
The DeepSeek-V3.2-Exp experiment belongs to a broader race in AI research: extending context windows while keeping models affordable. OpenAI’s GPT-4 Turbo, Anthropic’s Claude 3.5, and Google’s Gemini Ultra have all pushed context lengths beyond 100K tokens. But long memory isn’t free.
Each doubling of context usually doubles computational cost, memory footprint, and latency. Sparse attention architectures like DSA, Mistral’s Sliding Window, or Google’s FlashAttention 3 are all part of a collective effort to rewrite this scaling law. DeepSeek’s contribution is notable because it introduces a learned, fine-grained selection rather than a fixed pattern (like local windows). It allows the model itself, not the engineer, to decide what to ignore.
That autonomy could lead to more adaptable AIs that dynamically focus depending on the input type: a legal brief, a novel, or a source-code repository might each trigger different attention sparsity patterns.
The Lightning Indexer: A Closer Look
The lightning indexer deserves its own spotlight. It’s a small but crucial neural module that predicts relevance. Each “index head” computes a weighted dot-product between query and key representations, passes it through a ReLU activation, and sums across heads to produce an index score.
Because the indexer runs in FP8 precision and has relatively few heads, it’s extremely efficient. Yet its decisions shape the entire flow of computation. In a sense, it acts as a meta-attention layer, an attention mechanism deciding where attention should go.
This recursive structure hints at a deeper design philosophy: attention over attention. It may sound tautological, but it’s conceptually elegant. It allows the model to modulate its own cognitive bandwidth, similar to how humans allocate mental effort depending on task complexity.
The Science of Forgetting
In machine learning, forgetting is usually a bug; models lose knowledge when trained on new data. But selective forgetting, or pruning, can be a virtue. DeepSeek-V3.2-Exp formalizes forgetting as an algorithmic choice. By keeping only the top-k relevant tokens, it discards irrelevant noise.
This raises fascinating research questions: What does the model consider “important”? How does it decide when to drop a token? Preliminary experiments suggest it often preserves semantically rich anchors, topic sentences, key entities, or repeated motifs. The rest fade into latent silence. Over time, this selective memory could lead to emergent summarization abilities, where the model naturally compresses long texts without explicit supervision.
Reinforcement Learning and Balance
The unified RL stage introduced in V3.2-Exp is also philosophically interesting. Instead of separating reasoning, agentic behavior, and alignment into distinct stages (a common practice in large-model training), DeepSeek merged them. The resulting mixed RL allowed the model to develop skills synergistically rather than sequentially.
Reward functions included both rule-based metrics (for factual accuracy and code correctness) and generative reward models, AI judges that score responses according to human-like rubrics. The balance between conciseness and accuracy was fine-tuned with “length penalties.” This careful shaping of reward landscapes reveals how modern AI training resembles behavioral psychology: shaping tendencies through reinforcement rather than explicit instruction.
Economic and Environmental Impact
Efficiency isn’t just a bragging right, it’s an environmental and economic necessity. Training DeepSeek-V3.2-Exp on nearly a trillion tokens required vast GPU resources, but its inference efficiency makes deployment far cheaper. Reducing inference cost per million tokens from $2 to under $1 at 128K length translates into massive savings when running models at global scale.
Moreover, sparse attention’s lower energy footprint aligns with broader sustainability goals in AI. As models become infrastructure, even small efficiency gains ripple through the ecosystem like energy-saving LEDs in a global power grid.
From Experiment to Ecosystem
The paper calls this version “DeepSeek-V3.2-Exp”, the experimental edition. It’s a testbed for real-world validation. The authors explicitly invite large-scale testing to uncover limitations of sparse attention. That humility is refreshing in a field prone to overclaiming. Sparse models may still struggle with tasks requiring uniform coverage (like copying long sequences verbatim), or with edge cases where important information lies outside the top-k selection.
Yet if these limitations can be mitigated, through adaptive sparsity or hierarchical indexing, this approach could redefine how future foundation models handle long documents, videos, or multimodal streams.
Looking Forward: Toward Cognitive Efficiency
DeepSeek-V3.2-Exp represents more than an optimization. It signals a philosophical shift in how we think about artificial intelligence. Early neural networks thrived on abundance, more parameters, more data, more computation. But intelligence, natural or artificial, also depends on efficiency: the ability to ignore.
From the neurons in a human cortex to the lightning indexer of DeepSeek, the principle is the same: attention is precious. By formalizing selectivity into its architecture, DeepSeek moves closer to an AI that reasons not just powerfully but economically.
As the AI world races toward ever-longer contexts, million-token memories, lifelong learning agents, multimodal integration, models like DeepSeek-V3.2-Exp remind us that progress doesn’t always mean seeing more. Sometimes, it means knowing what not to look at.
Epilogue: The Lightning Metaphor
The paper’s title, “Boosting Long-Context Efficiency with DeepSeek Sparse Attention,” may sound dry, but the metaphor within it, the lightning indexer, is poetic. Lightning, after all, is fast, selective, and illuminating. It doesn’t light up the entire sky; it traces the most conductive path.
DeepSeek-V3.2-Exp embodies that same principle. In a world where data is infinite and computation costly, intelligence will belong not to the model that sees everything, but to the one that sees just enough, and does so in a flash.
References
[2] Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., ... & Xu, Z. (2024). Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434.
[3] Measuring Intelligence: Key Benchmarks and Metrics for LLMs, Transcendent AI
[4] Kullback, S., & Leibler, R. A. (1951). On information and sufficiency. The annals of mathematical statistics, 22(1), 79-86.
[5] Shazeer, N. (2019). Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150.
[6] Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., ... & Zeng, W. (2025). Native sparse attention: Hardware-aligned and natively trainable sparse attention. arXiv preprint arXiv:2502.11089.
[7] Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., ... & Tan, Y. (2025). Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081), 633-638.



Comments