
Understanding what the ML models have learned
- Juan Manuel Ortiz de Zarate

- Aug 2, 2024
- 10 min read
Updated: Aug 5, 2024
Ethics, derived from the Greek word "ethos" meaning character or custom, is a branch of philosophy concerned with defining and reasoning systematically about concepts of good and evil, and how these concepts can be applied to human conduct or the behavior of any moral agent. As machine learning becomes increasingly integrated into various aspects of our daily lives, ethical considerations in its application are becoming more crucial. Machine learning is now used in numerous areas, including autonomous vehicles, companion and caregiving robots, and financial services like loan approvals. However, the proliferation of ML in these domains has introduced significant ethical challenges.
The implementation of machine learning technologies can sometimes lead to discriminatory outcomes. Issues such as class discrimination[1], gender discrimination[2], racial discrimination[3], and manipulation [4] have been observed, raising concerns about the fairness and accountability of these systems. This article explores the importance of interpretability in machine learning, focusing on how tools like LIME (Local Interpretable Model-agnostic Explanations)[5] can help mitigate these issues by providing transparency and understanding in decision-making processes.
Key Issues in Machine Learning
1. Automated Decision-Making Based on Biases
The widespread deployment of machine learning systems for decision-making often relies on data that may be inherently biased. This can lead to automated decisions that reflect and perpetuate these biases on a large scale. For example, algorithms used in hiring, lending, and law enforcement have been found to disproportionately disadvantage certain groups based on gender, race, or socioeconomic status.
2. Reproduction and Exacerbation of Biases
Machine learning models can not only reproduce existing societal biases but also amplify them. This happens when algorithms, trained on biased data, make predictions or decisions that reinforce stereotypes and discrimination. For instance, a biased training dataset can lead to an AI system that systematically disadvantages certain demographic groups, thus perpetuating historical injustices and potentially making them worse.
3. Use of Models for Unethical Purposes
Beyond bias and discrimination, there is also the risk that machine learning models can be used for unethical purposes, known as "non-sanctus" uses. This includes deploying models in ways that violate privacy, manipulate public opinion, or enable surveillance and control. The use of AI in targeting political ads or spreading misinformation on social media are prime examples where the ethical boundaries of technology deployment are tested .
These issues highlight the critical need for interpretability and accountability in AI systems, ensuring that they are used fairly and ethically across various applications. Tools like LIME can help by making the decision-making processes of complex models more transparent and understandable, thus aiding in the detection and correction of biases.
Solutions
Social Solutions
Awareness of Impact: It is crucial for developers and organizations to understand the real-world implications of their work in AI. Recognizing that machine learning models can influence societal outcomes means accepting a shared responsibility for the ethical deployment of these technologies. This awareness can guide more thoughtful decision-making processes, ensuring that systems are designed and used with consideration for their broader effects.
Regulation of AI Model Production: as the power and reach of AI grow, there is an increasing call for regulatory frameworks that govern the development and deployment of AI systems. Such regulations could mandate transparency, fairness, and accountability, helping to prevent abuses and ensure that AI systems serve the public good. For example, guidelines[7] could be established to audit and test models for biases before they are deployed, ensuring they do not inadvertently harm vulnerable groups.

Technical Solutions
InterpretabilityInterpretability refers to the ability to understand and explain the decisions made by AI systems. It is essential for diagnosing and correcting biases within models. By making AI systems more transparent, stakeholders—including developers, regulators, and end-users—can gain insights into how decisions are made, identify potential issues, and take corrective actions.
FairnessEnsuring fairness involves creating models that do not systematically disadvantage certain groups. This can be achieved through techniques like adjusting for known biases in the training data, using fairness-aware algorithms, and continuously monitoring outcomes to detect and mitigate any discriminatory impacts.
Ethics by DesignEmbedding ethical considerations into the design phase of AI systems can prevent harmful outcomes. This approach advocates for the proactive integration of ethical guidelines throughout the development process, rather than treating ethics as an afterthought. This includes setting ethical objectives, designing systems that respect user privacy, and ensuring that the benefits and burdens of AI are distributed equitably.
In this article, we will focus on interpretability, specifically the LIME technique. It is a tool that helps explain the predictions of any machine learning classifier in an interpretable and faithful manner. It approximates the model locally by fitting an interpretable model around the prediction. This allows users to understand why a model made a particular decision, providing insights into the model’s behavior and helping to ensure that the system's decisions are just and unbiased. By focusing on LIME, we can explore how interpretability contributes to ethical and fair AI deployment.
Context
In many cases, the machine learning models that perform best and are eventually deployed into production are extremely complex. These models can contain millions of parameters, making them challenging to interpret and understand. This complexity often arises from the need to capture intricate patterns and relationships in large datasets, which simpler models may not be capable of doing. For instance, deep neural networks, particularly those used in natural language processing or computer vision, frequently have deep architectures with numerous layers and parameters, enabling them to achieve high levels of accuracy.

Furthermore, these advanced models are not always developed in-house. Organizations increasingly rely on pre-trained models or APIs provided by third-party vendors. These models are often trained on vast datasets by external entities and then fine-tuned for specific applications. While this can save time and resources, it also means that the inner workings of the models may not be fully understood by the end-users or developers. This lack of transparency can pose significant challenges when trying to ensure fairness, interpretability, and accountability in the models' outputs.
The complexity and opacity of these models underscore the importance of interpretability tools like LIME, which can help demystify the decision-making processes of these "black box" systems. By providing clear, local explanations for model predictions, LIME enables stakeholders to better understand and trust the outputs of complex models, even if they did not develop them from scratch.
The utility of machine learning models hinges on our ability to trust and understand them. Without this trust and understanding, deploying these models becomes risky and potentially dangerous. Even if a model shows high performance on a validation dataset, its behavior in real-world scenarios can be unpredictable and erratic. This discrepancy arises because validation datasets often fail to capture the full complexity and variability of real-world data, leading to unforeseen issues when the model is exposed to new, unseen situations.
Trusting a system blindly for decision-making can have severe consequences, particularly in critical fields like healthcare. For instance, relying on an opaque model for medical diagnosis without understanding its decision-making process could lead to misdiagnoses, adversely affecting patient care. This is especially concerning in scenarios where a wrong diagnosis could result in incorrect treatments, worsening a patient's condition or even leading to fatal outcomes.
Thus, the need for interpretability is paramount. It ensures that model predictions can be scrutinized, explained, and verified, allowing stakeholders to make informed decisions based on the model's outputs. This interpretability helps in identifying potential flaws or biases in the model, thereby preventing disastrous consequences in high-stakes applications.
LIME
A technique designed to make complex machine learning models more interpretable. The core objective of LIME is to identify an interpretable model that accurately represents the decision boundaries of the original complex classifier in a localized region. This means that for a given prediction, LIME attempts to approximate the behavior of the complex model using a simpler, more interpretable model, such as a linear model or decision tree, that can be understood by humans.
An interpretable explanation generated by LIME must be understandable to human stakeholders, regardless of the complexity of the underlying descriptors or features used by the model. For instance, even if the original model uses intricate mathematical representations or high-dimensional feature spaces, the explanation provided by LIME should be distilled into terms that are intuitive and easy to grasp. This is critical in applications where decision-making transparency is necessary, allowing users to see why a model made a certain prediction and to evaluate the reasonableness of that prediction.
By providing local explanations, LIME enables users to trust the model's decisions and understand the factors influencing those decisions, which is especially important in fields like healthcare, finance, and law, where decisions can have significant consequences.
Interpretable Features
In the context of LIME and machine learning interpretability, it's crucial to differentiate between features and the interpretable representation of data. Features refer to the variables or inputs used by a model to make predictions. These can often be complex and not easily understood by humans, especially when dealing with high-dimensional data or sophisticated transformations like embeddings.
An interpretable explanation is one that simplifies these features into a form that is easily understandable to humans, regardless of the complexity of the original features. The goal is to provide a clear and concise rationale behind the model's decision-making process.
Example
Consider a text classification task. The features used by the classifier might include embeddings generated by methods like Word2Vec [6], which transform words into dense numerical vectors capturing semantic meanings. While these embeddings are powerful for modeling, they are not easily interpretable by humans due to their complexity and high dimensionality.
In contrast, an interpretable representation for explaining a model's decision might involve using a binary vector that indicates the presence or absence of specific words in the text. This simpler representation helps humans understand the contribution of different words to the model's decision. For example, if a classifier is determining whether a movie review is positive or negative, an interpretable explanation might highlight that the presence of words like "excellent" or "terrible" played a significant role in the prediction.
By transforming complex features into more understandable representations, LIME allows users to gain insight into why a model made a particular decision, thus bridging the gap between model complexity and human interpretability.
Calculation
It works by approximating a complex model locally around a prediction. The key idea is to create a simpler, interpretable model that can mimic the behavior of the complex model in the vicinity of a particular instance. Here's a step-by-step explanation using mathematical notation:
Original Features and Model: Let x be the original instance, represented by a set of features x=[x_1,x_2,...,x_d]. The complex model f uses these features, potentially transformed through embeddings or other complex representations, to make predictions f(x).
Interpretable Representation: LIME requires defining an interpretable representation of the input, x. This interpretable version, x′=[x’_1,x’_2,...,x’_m], uses features that are easily understood by humans. For example, in a text classification task, x′ might be a binary vector indicating the presence or absence of specific keywords, while the complex model might use dense word embeddings generated by Word2Vec.
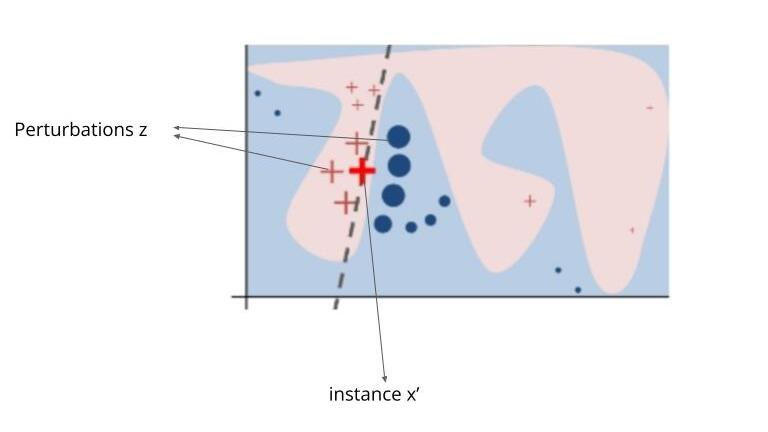
Mapping to Interpretable Features: During the perturbation step, the perturbed samples x'_i are generated in the space of interpretable features. These samples are then mapped back to the original feature space x_i using a function h_x(x'). The function h_x effectively translates the interpretable features back into the form required by the complex model:
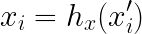
Weighting Samples: LIME assigns weights to these perturbed samples based on their proximity to the original instance x. The weight function π_x(z) measures the similarity between the perturbed sample z and the original instance x. This can be mathematically represented as:

where D(x,z) is a distance measure (such as Euclidean distance) and σ controls the width of the neighborhood.
Fitting a Simple Model: LIME then fits a simple, interpretable model g (such as a linear model) using the perturbed samples and their corresponding predictions from the complex model. The objective is to minimize the following loss function:

Here, G represents the family of interpretable models, Z is the set of perturbed samples, Ω(g) is a regularization term to ensure interpretability (penalizing complex explanations), and ξ is the explanation model that minimizes the weighted loss.
Generating Explanations: The output of LIME is the interpretable model g, which approximates f locally around x. The coefficients of g provide a human-understandable explanation of the features' contributions to the model's prediction for instance x.
By fitting the simpler model ggg to the complex model f within the neighborhood defined by πx, LIME produces explanations that are faithful to the original model's behavior in that local region. This approach helps users understand the decision-making process of complex, opaque models in a clear and interpretable manner.
Differentiating Siberian Huskies from Wolves
To illustrate how LIME can reveal unexpected behaviors in machine learning models, the authors of this technique applied it to a task where the goal was to differentiate between images of Siberian Huskies and wolves. Although the model might initially appear to perform well, LIME can help uncover the true features influencing its predictions.
LIME creates an interpretable explanation by using a simplified representation of the image. This is done by constructing a vector that indicates the presence or absence of small patches in the image. For each patch, LIME evaluates whether its presence significantly impacts the model's prediction, helping to identify which parts of the image are most influential.
Through this analysis, it was discovered that the model, which seemed to be functioning accurately, was actually relying on the presence of snow in the background to make its predictions. The classifier was correlating snowy backgrounds with the presence of wolves, due to the common association of wolves with wintry environments in the training data. Thus, the model was not actually differentiating based on the animals' physical features but was instead using the context (snow) as a shortcut for its decisions.

This finding highlights a common issue in machine learning known as "data leakage," where the model inadvertently learns to use irrelevant features—like the snow in this case—that happen to correlate with the target variable in the training set. LIME helps to expose these biases, providing critical insights into what the model is actually learning and ensuring that decisions are based on relevant, fair features. This transparency is vital for building trustworthy AI systems.
Conclusions
LIME is an effective method for interpreting the decision-making logic of a machine learning model f given a specific instance x. The primary goal of LIME is to identify which interpretable features are most influential in the model's inference process for the given instance. To achieve this, LIME generates perturbed instances z that are similar to xxx and uses a simple, interpretable model to approximate the behavior of the complex model f. By analyzing the impact of each feature on the predictions, LIME reveals which features significantly influenced the model's decision.
This approach helps in understanding whether a model is leveraging relevant information for its task or if it is overfitting to irrelevant or correlated data. For instance, LIME can uncover if a model is relying on non-informative features, such as background elements in images, rather than focusing on the essential characteristics necessary for accurate classification.
LIME stands out due to its simplicity and versatility. It can be applied to any type of model, regardless of the complexity or nature of the task at hand. This makes it a valuable tool for validating the fairness and reliability of machine learning systems, ensuring that they operate based on meaningful and justifiable criteria.
References
[3] Machine Bias
[5] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016, August). " Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
[6] Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.



Comments