
Language-Driven Precision in the Operating Room
- Juan Manuel Ortiz de Zarate

- Aug 13, 2025
- 10 min read
Recent advances in surgical robotics have shown promise [1, 2, 3], but most autonomous systems remain limited to short, highly controlled tasks. The Hierarchical Surgical Robot Transformer (SRT-H)[4] addresses this gap by enabling step-level autonomy in complex, long-duration procedures. Using a hierarchical design, SRT-H combines a high-level policy that plans in natural language with a low-level policy that executes precise robotic motions, allowing real-time self-correction. Trained via imitation learning on over 16,000 trajectories of ex-vivo gallbladder surgeries, the system achieved a 100% success rate across eight unseen specimens in the critical clipping-and-cutting phase of cholecystectomy. By generalizing across anatomical variations and recovering from errors without human intervention, SRT-H demonstrates the feasibility of autonomous execution in contact-rich surgical tasks. This work represents a milestone toward clinically viable autonomous surgery and illustrates the potential of language-conditioned, data-driven robotics to enhance precision, safety, and accessibility in the operating room.
1. Introduction
For decades, the idea of a surgical robot capable of performing complex procedures without constant human control has belonged more to science fiction than reality. While robotic systems like the da Vinci Surgical System have transformed operating rooms, they still rely on surgeons to guide every movement. Fully autonomous surgery has remained out of reach, limited by the unpredictable nature of human anatomy, the delicacy of tissue manipulation, and the need for flawless precision over long sequences of actions.
Most progress so far has been made in controlled environments or in highly simplified tasks, such as moving objects on a table or navigating rigid structures. But real-world surgery demands much more: the ability to adapt to variation between patients, operate in the presence of blood or smoke, and coordinate multiple instruments for minutes at a time without error.
The Hierarchical Surgical Robot Transformer represents a major step toward meeting these challenges. Developed by researchers at Johns Hopkins University, Stanford University, and Optosurgical, SRT-H uses a two-tiered approach: a high-level “planner” that thinks in natural language and a low-level “executor” that carries out precise, tool-level movements. This design enables the system not only to perform a surgical step from start to finish, but also to detect and correct its own mistakes along the way.
By focusing on one of the most delicate phases of gallbladder removal surgery, clipping and cutting the cystic duct and artery, the team tested SRT-H in realistic ex-vivo conditions, achieving perfect success across all trials without human intervention. This breakthrough suggests a future where surgical robots can handle complex, high-stakes tasks reliably, potentially expanding access to safe surgery worldwide.
2. System Overview
At the heart of the SRT-H is a simple but powerful idea: split the brain of the robot into two cooperating “minds,” each with its own specialty.
The high-level policy acts like a surgical coordinator. It observes the scene through multiple cameras, interprets what’s happening, and decides the next step, expressed as a short natural language instruction. This could be something like “apply the second clip to the artery” or “adjust the gripper to create more space.” The high-level system can also issue corrective instructions if it detects something has gone wrong, ensuring that errors are caught and fixed on the fly.
The low-level policy is the hands of the operation. It takes the high-level instruction and translates it into precise, continuous motions for the robot’s instruments. These movements are calculated from visual data, both the wide view from the endoscope and close-up views from small wrist-mounted cameras, without relying on special sensors or markers.
This hierarchical structure makes the robot more adaptable. Instead of trying to plan every detail at once, SRT-H breaks the operation into smaller, manageable steps, each of which can be executed and corrected before moving on. For training, the system learned from over 16,000 recorded demonstrations of real surgical actions on ex-vivo pig gallbladders, covering both ideal examples and recovery from mistakes.
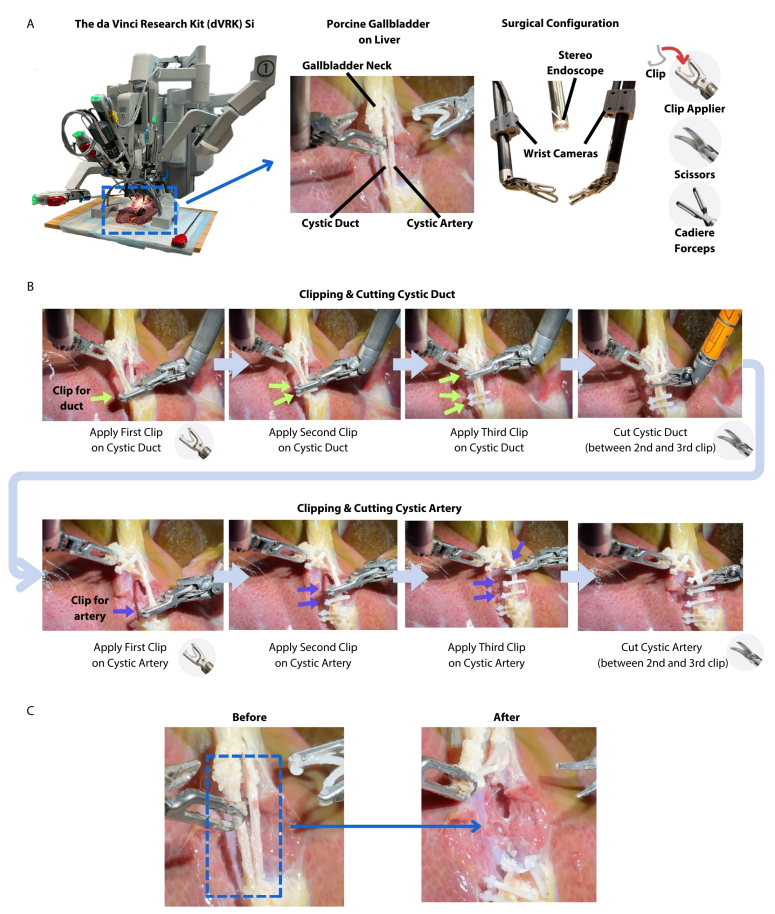
The physical setup uses the da Vinci Research Kit (dVRK), a widely used research platform for robotic surgery. It comes with standard surgical instruments, a stereo endoscope for the main view, and additional cameras mounted near the instrument tips to give the robot a detailed, “hands-on” perspective. In the clipping-and-cutting phase of gallbladder removal, the robot autonomously applies and positions six clips, three on the duct and three on the artery, and then performs two precise cuts between them, all while maintaining a safe distance from surrounding tissue.
By combining a language-driven planner with a motion-focused executor, SRT-H demonstrates how surgical robots can be both intelligent and precise, capable of handling long, complex steps while staying ready to adapt if the unexpected happens.
3. Hierarchical Architecture
The SRT-H is designed around the idea that complex surgery can’t be managed by a single, monolithic brain. Instead, it uses a two-tier control system, separating the role of deciding what to do next from the challenge of figuring out exactly how to do it. This approach mirrors the way a human surgical team works: the lead surgeon plans and directs the operation, while assistants execute the detailed, precise maneuvers.
![Model overview and architecture. (A) The architecture of our framework consists of a high-level policy that generates language instructions given the image observations, and a low-level policy that conditions on the language instructions and image observations to generate robot motions in Cartesian space. (B) On a more granular level, the high-level policy consists of a Swin-T model to encode the visual observations into tokens, that are processed by a Transformer Decoder to generate language instructions. The language instructions are processed by a pretrained and frozen distilled bidirectional encoder representations from transformers (DistilBERT[5]) model to generate language embeddings. The image observations are passed to an EfficientNet that conditions on the language embeddings through feature-wise linear modulation (FiLM) layers. The combined embeddings are passed to a Transformer Decoder to generate a sequence of actions that are encoded in delta position and orientation values.](https://static.wixstatic.com/media/ce3ed3_a99689711834430f9fbe7a25650cf5f7~mv2.png/v1/fill/w_980,h_535,al_c,q_90,usm_0.66_1.00_0.01,enc_avif,quality_auto/ce3ed3_a99689711834430f9fbe7a25650cf5f7~mv2.png)
At the high level (HL), SRT-H acts as the strategist. It takes in visual information from multiple sources—the wide, stereoscopic view of the surgical field and the close-up images from wrist-mounted cameras attached to the instruments. Using this visual input, the HL policy identifies the current state of the procedure and decides the next step. Importantly, it expresses that decision in natural language instructions. These are concise, task-specific phrases like “apply second clip to artery”, “move left gripper to create space”, or “go to cutting position on duct.” The use of language is not just for interpretability, it allows for a flexible, human-like interface where commands can describe a wide variety of situations, including recovery actions.
This self-correction capability is one of the HL’s defining strengths. If the system detects something is wrong, a clip slightly out of place, a tool in an awkward position, it can switch from giving a task instruction to giving a corrective instruction. This might be something like “adjust right arm leftward” or “reposition scissors”. The decision to send a corrective or task instruction is controlled by a “correction flag,” essentially a binary switch the HL sets based on its assessment of the current situation.
At the low level (LL), SRT-H becomes the executor. This is where the abstract instruction from the HL is translated into the fine-grained control of the robotic arms. The LL takes the natural language command, processes it alongside live visual data, and generates precise 3D motions, translations, rotations, and gripper movements, for each arm. It uses a transformer-based motion generation model that fuses the HL’s language embedding with image features through a method called Feature-wise Linear Modulation (FiLM)[6]. This fusion ensures that the robot’s physical movements are always grounded in both the real-time visual scene and the intended action plan.
The HL and LL work in a continuous feedback loop. Every three seconds, the HL reassesses the scene and either confirms the current plan or issues a new instruction. The LL then executes the instruction in small chunks, allowing for rapid adjustment if conditions change. This structure is especially important for surgery, where the anatomy can shift slightly, tissue can deform, and small slips in tool position can quickly become big problems if not corrected.
Training this hierarchy required not only thousands of ideal demonstrations but also a large number of recovery examples, scenarios where the robot was placed in a suboptimal state and the operator guided it back to a safe, correct position. These were collected using an iterative process called DAgger (Dataset Aggregation)[7]. In DAgger, the robot attempts to perform the task, experts correct its mistakes, and those corrections are added to the training set. Over time, this teaches the HL policy how to spot errors early and respond effectively, reducing the need for human intervention.
This hierarchical design solves a key challenge in robotic autonomy: the long-horizon problem. In surgery, tasks unfold over several minutes and involve dozens of micro-actions. If a single control policy tries to plan and execute everything at once, small errors accumulate, making failure almost inevitable. By breaking the job into clear, language-defined steps and pairing each with a specialized motion policy, SRT-H can maintain precision over long sequences, self-correct when needed, and adapt to the variability that defines real surgical environments.
In short, the hierarchical architecture gives SRT-H the strategic awareness of a seasoned surgeon and the steady hands of an expert assistant, an essential combination for any autonomous system aiming to operate safely inside the human body.
4. Experimental Validation
To truly assess whether SRT-H could handle the unpredictability and precision demands of real surgery, the researchers designed a rigorous evaluation focusing on one of the most delicate phases of laparoscopic gallbladder removal: the clipping and cutting of the cystic duct and artery. This stage is a natural stress test for an autonomous system, it requires identifying small, flexible structures, manipulating them without causing damage, and coordinating both robotic arms with millimeter accuracy. Any mistake, such as placing a clip too close to another or cutting in the wrong spot, could have severe consequences in a real patient.
The true test came when SRT-H was confronted with eight new gallbladders it had never seen before. Each presented its own challenges, differences in tissue color, duct and artery size, and even the angle at which structures were positioned. Despite this variability, the robot completed all 17 steps in each surgery, grabbing the gallbladder, placing six clips (three on the duct and three on the artery), and making two precise cuts, with a 100% success rate. No human intervention was required during the autonomous execution phase.
On average, SRT-H took about 317 seconds of active operation time per procedure (just over five minutes), excluding the brief pauses needed for an assistant to reload clips or change tools. What’s remarkable is how the system handled inevitable small errors. If a clip was slightly misaligned or an instrument was in a suboptimal position, the high-level policy detected the issue and issued a corrective instruction to the low-level policy, which then adjusted the robot’s trajectory. On average, each procedure involved about six self-corrections, small interventions that prevented mistakes from escalating.
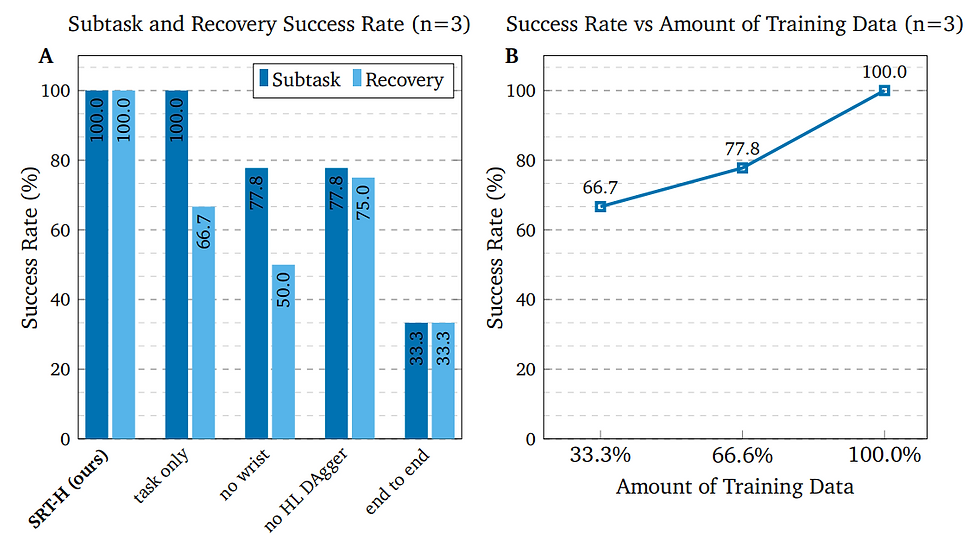
To understand which components of the architecture were most critical, the researchers performed ablation studies, testing simplified versions of SRT-H by removing specific features. Without the wrist-mounted cameras, performance dropped significantly, especially when recovering from mistakes, showing how vital close-up vision is for precise manipulation. Removing the corrective instruction mechanism led to more failed recoveries, confirming that self-correction is a cornerstone of the system’s reliability. End-to-end versions without the hierarchical split performed worst of all, struggling to manage the complexity of the task over time.

The team also compared SRT-H’s performance to that of an experienced human surgeon on the same gallbladder specimens. While the surgeon was faster overall, SRT-H often produced smoother, shorter instrument paths, with less abrupt movement, suggesting a more deliberate and consistent motion profile. Although speed remains an area for improvement, the robot’s precision and composure across multiple trials demonstrate a level of repeatability that could be invaluable in clinical practice.
These results paint a clear picture: SRT-H is not just capable of performing a complex, contact-rich surgical step; it can do so reliably, adapt to unexpected changes, and recover from its own mistakes, all essential traits for any system aspiring to operate in the unpredictable world of real surgery.
Conclusion
The work behind SRT-H shows that surgical autonomy is no longer a distant dream. By combining a language-driven high-level planner with a precise, vision-guided executor, the system can take on one of the most delicate steps in gallbladder surgery and perform it from start to finish, without a human hand on the controls and without sacrificing accuracy. In eight ex-vivo trials, it didn’t just succeed; it adapted, self-corrected, and delivered consistent results across different anatomies.
While there’s still a long road from the lab to the operating room, the implications are clear. A robot that can handle complex, contact-rich surgical tasks with this level of reliability could transform the way procedures are done. It could help standardize outcomes, reduce surgeon fatigue, and make advanced surgery more accessible worldwide. Of course, moving into real clinical environments will mean tackling challenges like bleeding, moving tissue, and tighter instrument constraints, as well as developing robust safety protocols.
SRT-H is not yet a replacement for a surgeon, and perhaps it never should be, but it’s a glimpse into a future where robots don’t just assist, but truly collaborate in the surgical process. It represents a shift from seeing autonomy as a technological curiosity to recognizing it as a practical, scalable tool for safer and more equitable healthcare.
References
[1] Scheikl, P. M., Gyenes, B., Younis, R., Haas, C., Neumann, G., Wagner, M., & Mathis-Ullrich, F. (2023). Lapgym-an open source framework for reinforcement learning in robot-assisted laparoscopic surgery. Journal of Machine Learning Research, 24(368), 1-42.
[2] Xu, J., Li, B., Lu, B., Liu, Y. H., Dou, Q., & Heng, P. A. (2021, September). Surrol: An open-source reinforcement learning centered and dvrk compatible platform for surgical robot learning. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 1821-1828). IEEE.
[3] Yu, Q., Moghani, M., Dharmarajan, K., Schorp, V., Panitch, W. C. H., Liu, J., ... & Garg, A. (2024, May). Orbit-surgical: An open-simulation framework for learning surgical augmented dexterity. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 15509-15516). IEEE.
[4] Kim, J. W., Chen, J. T., Hansen, P., Shi, L. X., Goldenberg, A., Schmidgall, S., ... & Krieger, A. (2025). SRT-H: A hierarchical framework for autonomous surgery via language-conditioned imitation learning. Science Robotics, 10(104), eadt5254.
[5] Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
[6] Perez, E., Strub, F., De Vries, H., Dumoulin, V., & Courville, A. (2018, April). Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1).
[7] Ross, S., Gordon, G., & Bagnell, D. (2011, June). A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics (pp. 627-635). JMLR Workshop and Conference Proceedings.



Comments