
The Curse of Dimensionality
- Juan Manuel Ortiz de Zarate
- Aug 14, 2024
- 10 min read
Updated: Aug 27, 2024
The curse of dimensionality[1] is a fascinating and critical concept in mathematics, statistics, and machine learning. It refers to the phenomenon where certain problems become exponentially more challenging as the number of dimensions, or features, increases. In this article, we will explore why higher dimensions complicate problems, using the intriguing analogy of a box containing a melon to illustrate how, in higher dimensions, a seemingly straightforward situation can become counterintuitive. We will also delve into the various effects of the curse of dimensionality in statistical analysis and machine learning, highlighting the difficulties and implications it poses in these fields.
At its core, the curse of dimensionality arises because the volume of space increases exponentially with the number of dimensions. This means that as the number of dimensions grows, the available space expands so rapidly that the data points we are interested in become sparse. To better understand this, consider the simple example of a box and a melon. In a low-dimensional space, such as three dimensions, it is easy to visualize a box that snugly fits around a melon. However, as we increase the number of dimensions, the volume of the box grows much faster than the volume of the melon. In a sufficiently high-dimensional space, the box contains far more "air" (empty space) than "melon" (actual data). This metaphor illustrates how, in higher dimensions, relevant data becomes a tiny fraction of the available space, making it increasingly difficult to analyze or make predictions.
The consequences of the curse of dimensionality are profound in various fields. In statistics, it affects the accuracy and reliability of models, as the sparsity of data in high-dimensional spaces makes it harder to detect meaningful patterns. Similarly, in machine learning, algorithms that work well in lower dimensions can struggle to generalize when applied to high-dimensional data. The curse of dimensionality can lead to overfitting, where a model becomes too complex and sensitive to the noise in the data, or underfitting, where it fails to capture the underlying patterns altogether.
In the following sections, we will delve deeper into these challenges and examine some of the specific effects of the curse of dimensionality on statistical analysis and machine learning techniques. We will also discuss strategies that researchers and practitioners can use to mitigate these challenges, including dimensionality reduction methods and regularization techniques. By the end of this article, you will have a comprehensive understanding of the curse of dimensionality, its implications, and how to address its challenges in practice.
Multidimensional mice
To further illustrate the concept of the curse of dimensionality, let's consider the case of "multidimensional mice" and how hunting them becomes increasingly difficult as the number of dimensions increases. This thought experiment helps us visualize how the challenges posed by higher dimensions manifest in a simple yet profound way.
Imagine a robot named Tom who lives in a one-dimensional universe. Tom's universe is confined to a straight line segment that is one meter long. One day, Tom spots a mouse that scurries back and forth along this line. Determined to catch the mouse, Tom decides to use his mouse-catching net, which has a length of 0.8 meters. Since Tom has no idea where the mouse will be at any given moment, he randomly throws his net in hopes of capturing it. The probability of Tom catching the mouse is directly proportional to the percentage of the line segment that his net covers. Mathematically, this probability is calculated as the ratio of the net's length to the length of the line segment:

In this one-dimensional scenario, Tom has a reasonably high chance of catching the mouse, with a probability of 0.8.
Now, let's add another dimension to the universe. Imagine that Minsky, another robot, lives in a two-dimensional space—a plane with dimensions of 1 meter by 1 meter. Minsky's mouse-catching net is now a square with side lengths of 0.8 meters. Just like Tom, Minsky doesn't know the exact location of the mouse, so he randomly places his net on the plane. The probability of Minsky catching the mouse is now calculated as the ratio of the area covered by the net to the total area of the plane:

Interestingly, as the number of dimensions increases, the "safe" area for the mouse becomes increasingly larger compared to the space occupied by the net. In two dimensions, the probability of catching the mouse has decreased from 0.8 to approximately 0.64. This decrease in probability continues as we move to higher dimensions.
If we extend this thought experiment to d dimensions, the probability of catching the mouse becomes:

This formula shows that the probability of success diminishes exponentially with the number of dimensions. In other words, as the number of dimensions increases, it becomes exponentially harder to catch the mouse. Even though the net's size remains the same relative to the dimension of space, the higher the dimensionality, the more "room" there is for the mouse to evade capture.
The graph shows how this probability fades away as we increase the number of dimensions.

It seems that in such high dimensions, there is no way to catch a mouse!
This image illustrates the same idea. As we go up in dimensions, the highlighted segment (the flycatcher) represents a smaller part of the total and the mouse has more room to roam:

In practical applications, this means that as we deal with more features or dimensions, our ability to effectively cover or analyze the space diminishes, leading to challenges in areas such as search algorithms, optimization, and machine learning.
Machine learning: desert spaces and empty neighborhoods
In the context of machine learning, the curse of dimensionality manifests itself in several ways, particularly through what can be described as "deserted spaces" and "empty neighborhoods." These challenges arise when the number of dimensions or features in a dataset increases without a corresponding increase in the number of data points, leading to significant complications in model training and performance.
Let’s break this down with a simple example. Suppose you are given a list of animals described by two attributes: weight and height. Each of these attributes can take on three possible values: low, medium, or high. Additionally, each animal is labeled as either a cat or a dog. The number of possible combinations of these attributes is calculated as:

With just a few dozen examples, you could begin to identify patterns and determine which combinations of weight and height are more likely to correspond to cats or dogs. The simplicity of this setup makes it relatively easy to train a classifier to distinguish between the two types of animals.
However, suppose you decide to improve your classifier by adding four more attributes: ear size, tail length, fur density, and number of hours spent sleeping. While these additional features might seem helpful at first glance, they significantly increase the complexity of the problem. The number of possible combinations of these attributes now becomes:
3 (weights) x 3 (heights) x 3 (ear sizes) x 3 (tail lengths) x 3 (fur densities) x 3 (sleep hours) = 729 combinations
The space of possible combinations has expanded from just 9 to 729. This exponential growth in the number of combinations poses a severe problem if the number of examples in your dataset remains limited. If you still only have, say, 10 examples, then the vast majority of these 729 possible combinations remain unexplored. In other words, your dataset is now spread too thin across a much larger space, making it difficult to generalize or make accurate predictions.
This brings us to one of the most troubling consequences of high-dimensional spaces: in high dimensions, everything is far from everything else. The concept of "neighborhoods" or "similarity" becomes almost meaningless. In lower dimensions, nearby points (in terms of attribute similarity) often indicate similar classifications. For example, if you have two animals with very similar weights and heights, it's reasonable to assume they might also share the same label (both being cats or both being dogs). However, in higher dimensions, the distance between points increases so drastically that it becomes challenging to find nearby points that are similar.
Some might suggest that expanding the neighborhood radius—essentially increasing the range within which you consider points to be neighbors—could help mitigate this issue. However, this approach introduces a new problem: if the radius is too large, you start to consider nearly every point as a neighbor to every other point. This dilutes the meaning of neighborhood, making it as ineffective as considering no neighborhood at all.
In essence, increasing the number of dimensions can "desertify" the feature space, turning it into a multidimensional version of a barren wasteland, reminiscent of a "Mad Max" scenario where meaningful relationships between data points are hard to find, and predictive accuracy becomes elusive.
To address this problem, there are two primary solutions. The first is to use fewer attributes—this can involve selecting only the most relevant features through techniques like feature selection or dimensionality reduction[3,4]. The second solution is to obtain more examples. Increasing the number of data points helps fill the expanded feature space, making it more likely that meaningful patterns can be detected and that the classifier can effectively generalize to new, unseen data.
The curse of dimensionality doesn't just complicate geometric or data-related problems—it also profoundly affects probability distributions, such as uniform and Gaussian distributions. In high-dimensional spaces, the concept of "mode" (the point of maximum probability density) becomes less useful, and we must shift our focus to the concept of "mass," which is the product of density and volume. This shift is crucial for understanding how probability behaves in high-dimensional settings.
Understanding Mass in High Dimensions
Before delving into specific distributions, it's important to clarify why mass becomes more important than density alone in high dimensions. The mode of a distribution is the point where the probability density is highest. However, in higher dimensions, even though the density at the mode might be high, the volume around this point shrinks rapidly. As a result, the total mass (which represents the actual probability in a region) near the mode may be relatively small. On the other hand, regions farther from the mode might have lower density but occupy much larger volumes, leading to a higher mass overall. This phenomenon indicates that most of the probability mass in high-dimensional spaces is often located away from the mode.
Let’s explore how this impacts two well-known probability distributions: the uniform distribution[5] and the Gaussian distribution[6].
Uniform Distribution
The uniform distribution is one where every point within a certain region (or space) has an equal probability density. In one dimension, this is simply a flat line over an interval, meaning that each point within the interval is equally likely. When we increase the number of dimensions, the uniform distribution extends over a higher-dimensional hypercube, where every point inside this hypercube still has the same probability density.
However, as the dimensionality increases, the situation changes drastically. Consider a uniform distribution over a d-dimensional hypercube where each side has a length of 1. The volume of this hypercube is 1, and every point within the hypercube has the same density. But as the number of dimensions increases, most of the volume of the hypercube is concentrated near its corners, far away from the center. This is counterintuitive because, in low dimensions, we tend to think of most of the mass being around the center of the distribution.
In high dimensions, the uniform distribution’s mass is increasingly concentrated in these peripheral regions. The proportion of the volume near the center of the hypercube shrinks rapidly, meaning that in a practical sense, if you were to sample from this distribution, you would rarely find points near the center. This illustrates how, in high dimensions, even though every point is equally likely in theory, the geometry of the space ensures that most points lie far from what we might consider the "typical" region.
Gaussian Distribution
The Gaussian distribution, also known as the normal distribution, is perhaps the most widely used probability distribution, characterized by its bell-shaped curve in one dimension. In higher dimensions, this distribution takes the form of a multivariate Gaussian distribution, which is centered around a mean vector with its probability density decreasing as you move away from the center.
In one or two dimensions, the majority of the probability mass of a Gaussian distribution is concentrated around the mean (center of the distribution). As you move away from the mean, the density decreases, and the probability of finding a point falls off rapidly.
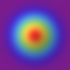
However, in higher dimensions, the story changes significantly. As dimensionality increases, the volume of the space increases exponentially. Even though the Gaussian distribution’s density still peaks at the mean, the volume of space around the mean becomes negligible compared to the total volume of the space. Thus, the probability mass, which is the product of density and volume, shifts away from the center.
For a high-dimensional Gaussian distribution, most of the mass is no longer near the mean but instead lies in a thin shell at a certain distance from the mean. This shell represents points that are not at the center but also not too far away—essentially, points that are at a moderate distance from the center, where the combination of density and volume is just right to maximize the mass. This phenomenon means that, in high dimensions, samples from a Gaussian distribution are likely to be found in this shell rather than close to the mean, contrary to what one might expect based on intuition from lower dimensions.
In both uniform and Gaussian distributions, increasing dimensionality dramatically alters the distribution of probability mass. In high-dimensional spaces, the mass of distribution shifts away from regions of high density (like the mode) and becomes concentrated in regions that, while having lower density, occupy much larger volumes. This shift challenges our traditional understanding of probability and necessitates new approaches to working with data in high-dimensional spaces. Understanding this is crucial for anyone working in fields like machine learning, where managing and interpreting high-dimensional data is a common task.
Conclusion
The curse of dimensionality is a pervasive phenomenon that impacts a wide array of mathematical, statistical, and machine learning problems. Geometrically, this concept can be vividly illustrated by the metaphor of a melon in a multidimensional box—where the box’s volume expands much faster than the volume of the melon, leading to a situation where there is far more "air" than "melon." This simple analogy captures the essence of how, in higher dimensions, relevant data or information becomes increasingly sparse and difficult to manage.
In statistics and machine learning, the curse of dimensionality presents significant challenges. While it might seem intuitive to think that adding more variables or features to a model would enhance its performance, this can often backfire if not accompanied by a proportional increase in data. As the number of dimensions grows, the space becomes more vast, and the data points that populate this space become more isolated. This sparsity turns the once manageable landscape into a barren desert, where making accurate predictions or drawing meaningful statistical inferences becomes exceedingly difficult.
Ultimately, the curse of dimensionality reminds us that more is not always better. In high-dimensional spaces, the volume grows so rapidly that most of it becomes empty, rendering traditional methods and intuitions less effective. The key to overcoming this challenge lies in balancing the complexity of our models with the availability of data, ensuring that we don’t venture too deep into the desert without the resources to navigate it.
References
[2] Betancourt, M. (2017). A conceptual introduction to Hamiltonian Monte Carlo. arXiv preprint arXiv:1701.02434.