
Make Neural Circuits Understandable
- Juan Manuel Ortiz de Zarate

- Nov 20, 2025
- 9 min read
Updated: Jan 1
Large language models (LLMs) have grown astonishingly capable, but not necessarily more comprehensible. Despite their fluency and reasoning prowess, they remain black boxes: vast webs of parameters whose inner workings defy intuitive grasp. In response, the field of mechanistic interpretability has emerged, aiming to reverse-engineer neural networks and map their internal algorithms to human-understandable concepts. Yet even with years of progress, the internal “circuits” of dense models remain tangled and opaque.
A new paper from OpenAI, “Weight-Sparse Transformers Have Interpretable Circuits”1, proposes a radically simple, but powerful, idea: if you want neural networks to think more transparently, build them to think sparsely. By forcing most of a model’s weights to zero, each neuron becomes more selective and each connection more meaningful. The result is a transformer whose internal circuits can be visualized, described, and, crucially, understood 2.
This work marks a milestone in interpretability research. It introduces models that not only perform nontrivial language tasks but also reveal their inner logic, down to individual neurons and attention heads. These sparse transformers illuminate how complex behaviors, like closing quotes in strings, counting nested lists, or tracking variable types, can emerge from simple, human-traceable algorithms.

The Motivation: From Black Boxes to Transparent Machines
The central frustration in modern AI is that we can’t easily say how or why large models make decisions. Neurons in dense networks activate in overlapping patterns that don’t correspond to discrete concepts. This phenomenon, called superposition3, means multiple ideas are entangled in the same representational space. For instance, a single neuron might partly represent both “an opening quote” and “a variable name,” depending on context.
Interpretability researchers have long tried to untangle these representations using techniques like sparse autoencoders (SAEs)4, which learn a new basis where activations are sparse. But such methods rely on learned abstractions, meaning they may reflect artifacts of the interpretability model itself rather than the true mechanisms inside the network.
Gao and colleagues take a different approach: instead of learning sparsity after training, they build it into the model from the start. By training transformers with a strict constraint on the number of nonzero weights (their L₀ norm), they force each neuron to connect to only a few others. This creates what they call weight-sparse transformers, models whose architectures are minimalistic by design. The aim is not efficiency; it’s clarity.
How to Train a Sparse Mind
The researchers trained GPT-2–style decoder-only transformers5 on Python code, varying how many weights were allowed to remain nonzero. The sparsest models had about 1 in 1,000 active weights, and even their activations were lightly constrained, with roughly one in four nonzero values per layer.
After pretraining, they probed the models on a suite of 20 deliberately simple but diagnostic binary tasks, such as predicting whether a Python string opened with a single or double quote, or deciding whether a variable called current should be followed by .add or +=. Each task isolates a specific kind of reasoning the model might perform internally.
To measure interpretability, they devised a pruning method that identifies the smallest set of neurons and connections necessary to maintain performance on a task. These reduced subnetworks, circuits, represent the minimal “wiring diagram” for the behavior. Circuits that are both compact and human-comprehensible are considered highly interpretable.
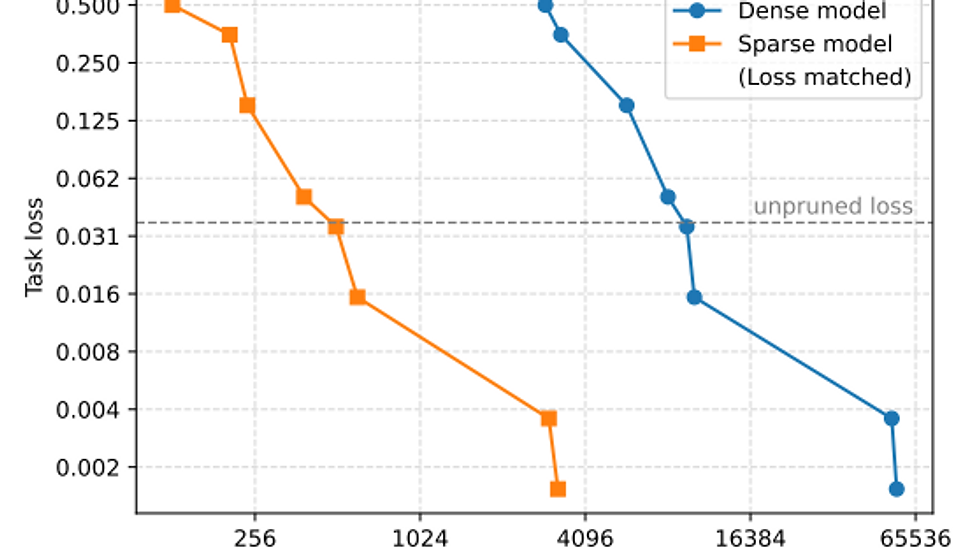
The metric of interpretability, then, is the geometric mean of circuit size (measured by the number of edges) across all tasks. Sparse transformers produced circuits roughly 16 times smaller than their dense counterparts at the same loss level, a striking difference.
Disentangling Behavior: The Birth of Understandable Circuits
1. The String-Closing Circuit
One of the simplest tasks tested whether a model could correctly close a string opened with either ' or ". The sparse model learned a clean two-step algorithm involving just two neurons and one attention head.
The first neuron, located in an early MLP layer, acted as a “quote detector”, firing for both single and double quotes. The second neuron, the “quote type classifier,” distinguished between them. An attention head then used the detector as a key and the classifier as a value: later tokens attending to the opening quote could copy the correct type to produce the matching closing quote.
When the authors ablated these neurons, performance collapsed. When they ablated everything except them, the task performance remained intact. The circuit, shown in full in the paper’s diagram, was so simple it could be traced entirely by hand.

2. Counting Nested Lists
A more challenging circuit emerged for the task of deciding whether to close a list with ] or ]]. Here, the model had to count the nesting depth of brackets, a primitive form of memory. The circuit performed this in three stages:
Embedding: the model used token embeddings to detect open brackets, writing their presence to specific residual channels.
Counting: an attention head averaged these signals across the sequence, producing a continuous measure of “list depth.”
Thresholding: another head compared this depth to a threshold, deciding whether a nested list required ].
This miniature algorithm is a marvel of self-organization: the model spontaneously built a computational graph resembling a counter. The researchers then used their understanding to design adversarial examples, injecting distracting brackets earlier in the sequence to trick the model into overcounting. The attacks worked exactly as predicted, validating that their circuit-level understanding was not just descriptive but causal.
3. Tracking Variable Types
In another experiment, the model distinguished between code lines like current = set() and current = "", then later decided whether to use .add or +=. The sparse model built a two-hop attention mechanism: one head copied the variable name into the location of its value; another later retrieved it to recall its type. Again, a simple and interpretable algorithm emerged from sparse wiring.
The Tradeoff: Capability vs. Interpretability
Sparsity makes reasoning visible, but at a cost. Sparse models are computationally inefficient and less capable for the same parameter count. Yet the researchers found that scaling model width while keeping sparsity fixed improves both interpretability and capability. In other words, bigger sparse models sit on a better capability–interpretability frontier: they can do more without sacrificing clarity.

When plotted, this tradeoff resembles a Pareto frontier, moving “down and left” means achieving better interpretability (smaller circuits) without losing performance. Sparse models outperform dense ones across this curve. Still, scaling beyond tens of millions of nonzero parameters remains a challenge, both technically and financially.
Bridging the Gap: Explaining Dense Models with Sparse Ones
Training new sparse models from scratch is valuable for science but impractical for industry. Most high-performing systems are dense. To connect theory with reality, the authors introduce a clever mechanism called bridges: mappings between activations of a dense model and its sparse counterpart.
Each bridge acts like a translator. During joint training, a sparse model learns to replicate the behavior of a dense one while a set of encoders and decoders map their respective activations layer by layer. Once trained, perturbations made in the sparse model, such as turning up the “quote type” neuron, can be projected into the dense model to see if its behavior changes accordingly.
In experiments, these interpretable perturbations worked. For instance, nudging the “quote classifier” channel in the sparse model made the dense model more likely to produce a single quote instead of a double quote, even when given the same prompt. Similarly, tweaking the channel representing whether a line began with while or return shifted the dense model’s likelihood of outputting a colon. This suggests that sparse analogues can serve as interpretable stand-ins for opaque networks.
The Vision: Toward Model Organisms for AI Interpretability
Gao and colleagues frame their sparse transformers as “model organisms”, simpler, interpretable analogues of complex systems. Just as biologists study fruit flies to infer insights about mammals, interpretability researchers might study sparse models to discover universal circuit motifs that recur in large LLMs.
If these motifs generalize, say, a recurrent “counter circuit” or “copy circuit” across scales, then understanding small sparse networks could unlock the principles of much larger ones. Sparse “model organisms” might eventually reach the sophistication of GPT-3, allowing researchers to map the anatomy of intelligence without needing to dissect trillion-parameter brains directly.
Another potential application is task-specific interpretability. Instead of trying to understand a model’s entire cognition, researchers could train sparse, bridged models on narrow but critical domains, like deception, goal-seeking, or refusal, to audit how such behaviors emerge mechanistically. This would make interpretability a safety tool, not just a scientific pursuit.
Limitations and Open Challenges
The authors are candid about the limits of their approach.
Compute inefficiency: Sparse networks require 100–1000× more computation to train and run than dense ones with equivalent performance. Optimizing and deploying them at scale is currently infeasible.
Residual polysemy: Even in sparse models, not every neuron is purely monosemantic (one concept per neuron). Some features still blend multiple meanings, suggesting that complete disentanglement may be unnatural, or even undesirable, for efficient computation.
Faithfulness testing: The pruning method relies on mean ablation, freezing pruned nodes at their average activation, to verify that circuits are necessary and sufficient. While this provides good evidence, it doesn’t guarantee perfect causal faithfulness. More rigorous methods, such as causal scrubbing, are needed.
Scaling to complex tasks: For small programs and code snippets, circuits remain tractable. But for richer linguistic tasks or multi-step reasoning, circuits could balloon into thousands of components. At some scale, human understanding might give way to automated interpretability, machines explaining machines.
Context Within the Field
This work sits at the intersection of three major research threads:
Mechanistic interpretability, which seeks to reverse-engineer models at the level of neurons and attention heads (pioneered by Olah6, Dunefsky8, Sharkey7, and others).
Sparse autoencoder research, which uses dictionary learning to find disentangled representations inside dense models.
Sparse training and pruning, a classic domain studying how to reduce model size while retaining performance.
Previous works like Sparse Feature Circuits (Marks et al., 2024) or Attribution Graphs (Ameisen et al., 2025) produced interpretability advances but still relied on abstractions over dense networks. Gao et al.’s contribution is to make sparsity the architecture itself, yielding circuits simple enough to map in their entirety, sometimes down to a dozen edges.
Their experiments also tie into automated interpretability. Sparse circuits offer a new substrate for algorithmic discovery: by providing clearer primitives (monosemantic neurons, simple edges), they make it easier for future systems to automatically identify and name concepts.
The broader vision here is profound. If we can see what a model knows, we can begin to trust or correct it. Sparse transformers turn opaque statistical machines into legible cognitive systems, blueprints for reasoning that can be verified, debugged, and, eventually, aligned with human values.
There’s also a philosophical echo of Occam’s razor: simplicity enables understanding. The more entangled a mind, artificial or biological, the harder it is to explain. Weight sparsity enforces a kind of digital parsimony; each connection must mean something.
At the same time, sparsity challenges the assumption that interpretability must come after capability. Instead of peeling back the layers of already inscrutable systems, we might build transparency in from the start. It’s a shift from interpretability as forensics to interpretability as design principle.
In their discussion, the authors imagine a future where sparse circuits become a common interpretability primitive, a language in which neural computations can be expressed. Just as electrical engineers diagram circuits to describe function, AI researchers might someday sketch attention heads and MLP neurons as logic gates in cognitive schematics.
Such representations could underpin automated interpretability, systems that not only read models but explain them, translating circuits into natural-language explanations or symbolic programs. Sparse networks, with their modular and comprehensible wiring, could serve as training grounds for this next leap.
Conclusion
The paper “Weight-Sparse Transformers Have Interpretable Circuits” redefines what it means for a neural network to be understood. By building transformers where almost every weight is zero, Gao and collaborators transformed the abstract goal of interpretability into a concrete engineering reality. Their models learn simple, disentangled circuits whose operations can be visualized, verified, and reasoned about.
While still far from matching the performance of dense frontier models, these weight-sparse networks mark a paradigm shift: they demonstrate that neural cognition need not be forever hidden. Complexity, it seems, is not the enemy of understanding; entanglement is. And by pruning it away, we may finally begin to see the logic behind the language of machines.
References
1] Gao, L., Rajaram, A., Coxon, J., Govande, S. V., Baker, B., & Mossing, D. (2025). [Weight-sparse transformers have interpretable circuits. OpenAI. arXiv preprint arXiv:2511.13653. https://arxiv.org/abs/2511.13653
3] Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., ... & Olah, C. (2022). [Toy models of superposition. arXiv preprint arXiv:2209.10652.
4] Ng, A. (2011). [Sparse autoencoder. CS294A Lecture notes, 72(2011), 1-19.
5] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). [Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
6] Olah, C., Turner, N. L., and Conerly, T. [A toy model of interference weights. https://transformer-circuits.pub/2025/interference-weights/index.html, 7 2025. Transformer Circuits.
7] Sharkey, L., Braun, D., and Millidge, B. [Taking features out of superposition with sparse autoencoders. AI Alignment Forum, 2022.



Comments