
The Power of Convolutional Neural Networks
- Juan Manuel Ortiz de Zarate

- Apr 26, 2025
- 10 min read
Updated: Apr 29, 2025
In the landscape of modern artificial intelligence, few innovations have been as transformative as Convolutional Neural Networks (CNNs). Originally inspired by the visual cortex of animals, CNNs have evolved to become the backbone of computer vision, enabling machines to recognize images, detect objects, and even generate realistic visuals. This article delves into the architecture, key concepts, applications, and the future potential of CNNs.
A Brief History of CNNs
The history of Convolutional Neural Networks reflects the broader evolution of artificial intelligence, marked by early visionary ideas, technological limitations, and a series of breakthroughs that ultimately reshaped the field.
Early Inspirations
The fundamental idea behind CNNs comes from neuroscience. In 1962, Hubel and Wiesel [1]conducted groundbreaking experiments on the visual cortex of cats, discovering that individual neurons responded selectively to specific visual stimuli, such as oriented edges. Their work laid the biological foundations for the concept of local receptive fields, which would later inspire artificial neural network architectures [10].
Throughout the 1970s and 1980s, researchers attempted to build computational models of vision, but progress was slow due to limited computing resources and a lack of large datasets.
The Birth of CNNs: LeNet-5
In 1989, Yann LeCun, working at Bell Labs, introduced one of the first practical CNN architectures: LeNet-5 [2]. Designed for handwritten digit recognition, particularly for zip code classification by the U.S. Postal Service, LeNet-5 embodied key principles that define CNNs today:
Convolutional layers to detect features.
Subsampling (pooling) layers to reduce spatial dimensions.
Fully connected layers to perform classification.

LeNet-5 demonstrated the feasibility of end-to-end learning for image classification. However, due to hardware constraints and the lack of large labeled datasets, CNNs remained a niche technology during the 1990s.
The Deep Learning Winter
From the mid-1990s to the early 2000s, neural networks, including CNNs, fell out of favor. Traditional machine learning methods such as Support Vector Machines (SVMs) and Random Forests outperformed neural networks on many benchmarks. Researchers faced several barriers:
Vanishing gradients made training deep networks unstable.
Overfitting was a serious issue, exacerbated by small datasets.
Computational power was insufficient for large-scale deep learning.
This period, often referred to as an "AI winter" for neural networks, delayed the widespread adoption of CNNs.
The Breakthrough: AlexNet
Everything changed in 2012 when Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton developed AlexNet [3] and entered it into the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
Key innovations in AlexNet included:
Deep architecture: 8 layers (5 convolutional + 3 fully connected).
ReLU activations: The introduction of the rectified linear unit (ReLU) significantly sped up training.
Dropout regularization: Dropout was used to combat overfitting.
GPU acceleration: Training was parallelized across two GPUs, reducing training time from weeks to days.
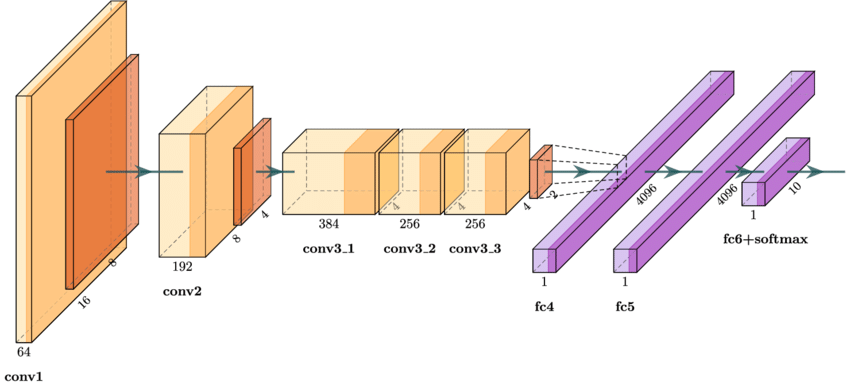
AlexNet reduced the top-5 error rate in ImageNet classification from 26% (previous best) to 15%, a staggering improvement that stunned the research community.
This moment marked the beginning of the deep learning revolution.
Rapid Innovation: VGGNet, GoogLeNet, and ResNet
Following AlexNet’s success, the field moved rapidly:
VGGNet (2014), developed by the Visual Geometry Group at Oxford, demonstrated that deeper networks (16–19 layers) with small 3x3 convolutions could achieve even better performance.
GoogLeNet (2014) introduced the Inception module, a way to optimize the network’s use of computation by combining multiple convolutional operations in parallel, leading to more efficient deep models.
ResNet (2015), developed by Microsoft Research, introduced residual connections, solving the problem of vanishing gradients and enabling networks with over 150 layers. ResNet’s innovation made it possible to train extremely deep models without degradation.
Each of these architectures represented a leap in understanding how to build deeper, more powerful, and more efficient CNNs.
CNNs Beyond Vision
Although CNNs originated in computer vision, by the late 2010s they began expanding into other fields:
Audio processing: Spectrograms of audio signals could be treated like images and analyzed with CNNs.
Natural language processing: CNNs were adapted for sentence classification, especially where capturing local patterns (like phrases) was important.
Medical imaging: CNNs enabled breakthroughs in automated diagnosis, from detecting diabetic retinopathy to identifying cancers in radiology scans.
The Modern Era
Today, CNNs remain foundational in AI, even as new architectures like transformers gain prominence. Research continues to refine CNNs, making them:
Lighter and faster (e.g., MobileNet, EfficientNet).
More interpretable, using techniques like Class Activation Mapping (CAM).
More adaptable, integrating attention mechanisms and hybrid approaches.
Despite competition from other architectures, CNNs are embedded deeply into the AI ecosystem and continue to power critical applications from self-driving cars to video surveillance and medical diagnostics.
Core Concepts of CNNs
At their heart, CNNs are designed to process data with a grid-like topology, such as images. They are fundamentally different from traditional fully connected neural networks because they take advantage of the spatial structure in input data. Rather than connecting every input to every neuron, CNNs exploit local correlations by enforcing a sparse interaction and parameter sharing scheme.

CNNs are built from several key types of layers:
Convolutional Layers
The convolutional layer is the cornerstone of a CNN. It applies a set of learnable filters (also called kernels) that slide over the input data to produce feature maps. Each filter specializes in detecting specific features like edges, corners, or textures. As the network deepens, later layers capture more abstract patterns such as object parts or even entire objects.
Mathematically, a 2D convolution operation between an input image and a kernel is defined as:

Where:
I is the input image,
K is the convolutional kernel
S is the output feature map.
Important hyperparameters in convolutional layers include:
Stride: Determines how much the filter moves at each step. A stride greater than 1 reduces the output size.
Padding: Adding extra border pixels to preserve spatial dimensions.
Dilation: Expanding the receptive field without increasing the number of parameters.
Convolutions enable CNNs to be translation invariant, meaning that small shifts in the input do not dramatically change the output.
Activation Functions
After applying convolution, CNNs typically use a non-linear activation function, most commonly the Rectified Linear Unit (ReLU):
f(x)=max(0,x)
ReLU introduces non-linearity to the model, allowing it to learn complex functions. Other activations like Leaky ReLU, ELU, or GELU can also be used depending on the problem.
Pooling Layers
Pooling layers are used to progressively reduce the spatial size of the representation, decreasing the number of parameters and computation, and controlling overfitting.
The most common types of pooling are:
Max Pooling: Selects the maximum value from each patch of the feature map.
Average Pooling: Computes the average of the values in each patch.
Pooling introduces a form of local translation invariance, meaning that small distortions or shifts in input do not affect the pooled representation much.
Fully Connected Layers
Fully connected (FC) layers, often found toward the end of CNNs, interpret the high-level features extracted by convolutional and pooling layers and perform the final classification or regression task.
Each neuron in an FC layer is connected to every neuron in the previous layer, resembling the architecture of a traditional multilayer perceptron. However, the heavy lifting of feature extraction has already been performed by the earlier convolutional layers, making the FC layers relatively lightweight.
Normalization Layers
Modern CNNs often incorporate normalization techniques, such as Batch Normalization. This layer normalizes the output of previous layers to have zero mean and unit variance, stabilizing and speeding up training.
Dropout Layers
To prevent overfitting, dropout randomly disables a fraction of neurons during training. By forcing the network to be redundant and robust, dropout enhances generalization to unseen data.
Hierarchical Feature Learning
One of the most powerful aspects of CNNs is their ability to learn hierarchical features:
Early layers detect edges and simple textures.
Intermediate layers capture patterns like corners, contours, and object parts.
Deeper layers assemble these parts into full object representations.
This hierarchy enables CNNs to generalize remarkably well across various visual tasks, from simple classification to complex object detection.
Key Innovations in CNN Design
Since the introduction of LeNet and AlexNet, many architectures have pushed the boundaries of what CNNs can achieve. Researchers have systematically addressed challenges such as computational cost, vanishing gradients, and limited generalization, resulting in innovative designs that have broadened the applicability of CNNs across tasks.
Some landmark models include:
VGGNet (2014)
Proposed by the Visual Geometry Group at Oxford, VGGNet [4] demonstrated that network depth is crucial for good performance. VGG architectures use stacks of small 3x3 convolutional filters instead of larger ones, dramatically improving performance while maintaining manageable computational complexity. The network is uniform and simple, making it highly popular for feature extraction in transfer learning.
Key Contributions:
Standardized the use of small (3x3) convolutions.
Showed that depth improves representation power.
Emphasized simplicity and modularity in network design.
GoogLeNet / Inception (2014)
GoogLeNet [5], developed by Google Research, introduced the Inception module. Instead of choosing a single filter size for each layer, Inception modules perform multiple convolutions (1x1, 3x3, 5x5) and pooling in parallel, then concatenate the outputs. This approach allows the network to learn multi-scale features at every level while maintaining computational efficiency.

Key Contributions:
Introduced Inception modules to combine multiple filter operations.
Used global average pooling to replace fully connected layers, reducing the number of parameters.
Achieved state-of-the-art performance with significantly fewer parameters than VGGNet.
ResNet (2015)
Training deep neural networks is notoriously difficult due to problems like vanishing gradients. ResNet (Residual Networks)[6] addressed this by introducing residual connections: shortcuts that allow gradients to bypass one or more layers.
In a residual block, instead of learning an unreferenced mapping H(x), the network learns F(x)=H(x)−x, and thus H(x)=F(x)+x.
Key Contributions:
Solved the degradation problem, enabling very deep networks (up to 152 layers).
Introduced skip connections that made backpropagation through deep networks feasible.
Became a backbone for many subsequent architectures, from object detection to image segmentation.
DenseNet (2017)
DenseNet [7] extended the idea of connectivity by linking each layer to every other layer in a feed-forward fashion. In DenseNets, the input to each layer is the concatenation of all previous layers' outputs, encouraging maximum feature reuse.
Key Contributions:
Improved information flow between layers.
Mitigated the vanishing gradient problem even further.
Achieved high parameter efficiency by reducing redundancy.
Other Notable Innovations
MobileNet [8]: Introduced depthwise separable convolutions, drastically reducing computation for mobile and embedded applications.
EfficientNet [9]: Proposed a principled way to scale networks in depth, width, and resolution simultaneously.
SqueezeNet: Achieved AlexNet-level accuracy with 50x fewer parameters by using "fire modules" (1x1 convolutions followed by 3x3 expansions).
Each of these models contributed important ideas that addressed specific limitations in earlier designs, leading to CNNs that are deeper, faster, more accurate, and more efficient.
Today, many advanced systems use hybrid models that integrate CNNs with components like attention mechanisms or transformers, continuing the tradition of innovation.
CNNs in Practice: Training and Optimization
Training a CNN involves minimizing a loss function (e.g., cross-entropy for classification) through backpropagation and gradient descent. Several strategies have proven essential for effective training:
Data Augmentation: Expanding the training set with modified versions of images (rotations, flips, crops) to improve generalization.
Batch Normalization: Normalizing layer inputs to accelerate training and improve stability.
Dropout: Randomly "dropping" neurons during training to prevent overfitting.
Learning Rate Schedulers: Dynamically adjusting the learning rate during training to fine-tune convergence.
Applications of CNNs
CNNs have powered many breakthroughs across different industries:
Computer Vision
Image Classification: Assigning a label to an image (e.g., identifying objects, animals).
Object Detection: Locating objects within an image (e.g., YOLO, Faster R-CNN).
Image Segmentation: Classifying each pixel in an image (e.g., U-Net for medical imaging).
Beyond Vision
Natural Language Processing: CNNs have been used for sentence classification and character-level language modeling.
Reinforcement Learning: In DeepMind’s AlphaGo, CNNs played a key role in evaluating game states.
Healthcare: Automated diagnosis of diseases from medical imaging (e.g., cancer detection).
Challenges and Limitations
Despite their success, CNNs are not without limitations:
Data Hunger: CNNs require large amounts of labeled data to achieve good performance.
Interpretability: Understanding exactly what features a CNN is learning remains difficult.
Vulnerability to Adversarial Attacks: Slight perturbations to input images can fool CNNs into making incorrect predictions.
Computational Costs: Training large CNNs demands powerful GPUs and substantial energy resources.
These challenges have led to the exploration of new methods like self-supervised learning and more efficient network designs.
Advances and Trends
Recent research aims to overcome CNNs’ limitations and expand their capabilities:
Attention Mechanisms: Borrowed from transformer models, attention mechanisms allow CNNs to focus on important regions of an image.
Efficient CNNs: Architectures like MobileNet and EfficientNet are optimized for deployment on mobile devices.
Self-supervised CNNs: New training techniques enable CNNs to learn useful representations without requiring labeled datasets.
Hybrid Models: Combining CNNs with transformers has produced powerful vision models like Vision Transformers (ViT) and ConvNext.
Moreover, 3D CNNs are increasingly used in video processing and volumetric medical imaging, opening up new frontiers.
The Future of CNNs
The future of CNNs is closely tied to how well they adapt to broader AI trends:
Generalization Across Domains: Models that can adapt from images to videos, text, and other modalities will be highly valuable.
Explainability and Trust: Developing tools to make CNNs’ decision processes transparent will be crucial, especially in critical fields like healthcare.
Resource Efficiency: As concerns about AI’s carbon footprint grow, lightweight and energy-efficient CNN architectures will become essential.
While transformers currently dominate headlines, CNNs continue to evolve and will likely remain a core tool in the AI toolbox for years to come.
Conclusion
Convolutional Neural Networks have revolutionized how machines perceive and interact with the world. Their impact spans from academic research to everyday technologies, demonstrating the profound power of biologically inspired computation. As new challenges emerge, CNNs are adapting, integrating with new ideas, and pushing the boundaries of what artificial intelligence can achieve. Far from being replaced, they are being reimagined for the next generation of AI innovation.
References
[1] Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. The Journal of physiology, 160(1), 106.
[2] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
[3] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
[4] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[5] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[6] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[7] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
[8] Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., ... & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
[9] Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (pp. 6105-6114). PMLR.
[10] The Brains Behind AI’s Evolution, Transcendent AI
[11] Strisciuglio, N., Lopez-Antequera, M., & Petkov, N. (2020). Enhanced robustness of convolutional networks with a push–pull inhibition layer. Neural Computing and Applications, 32(24), 17957-17971.
[12] 2D Convolution Animation, Wikimedia Commons



Comments